Goal
For some time I have been working mostly within the Google Cloud ecosystem, which gradually pulled me away from a few tools commonly used in data engineering. I decided to brush up my knowledge of Apache Spark, Delta Lake and GitHub Actions.
I used Claude Code as a guide, turning the project into a kind of practical class that sped up development and reinforced some concepts. With the rise of AI, building solutions has become increasingly simple. Even so, knowing the technologies behind it still matters when it comes to discussing, questioning and steering what gets delivered.
I defined three items for the test: a public dataset, a pipeline able to run automatically, and a final output that would deliver at least some value. Since I work with logistics and transportation costs, I chose US fuel prices.
What It Does
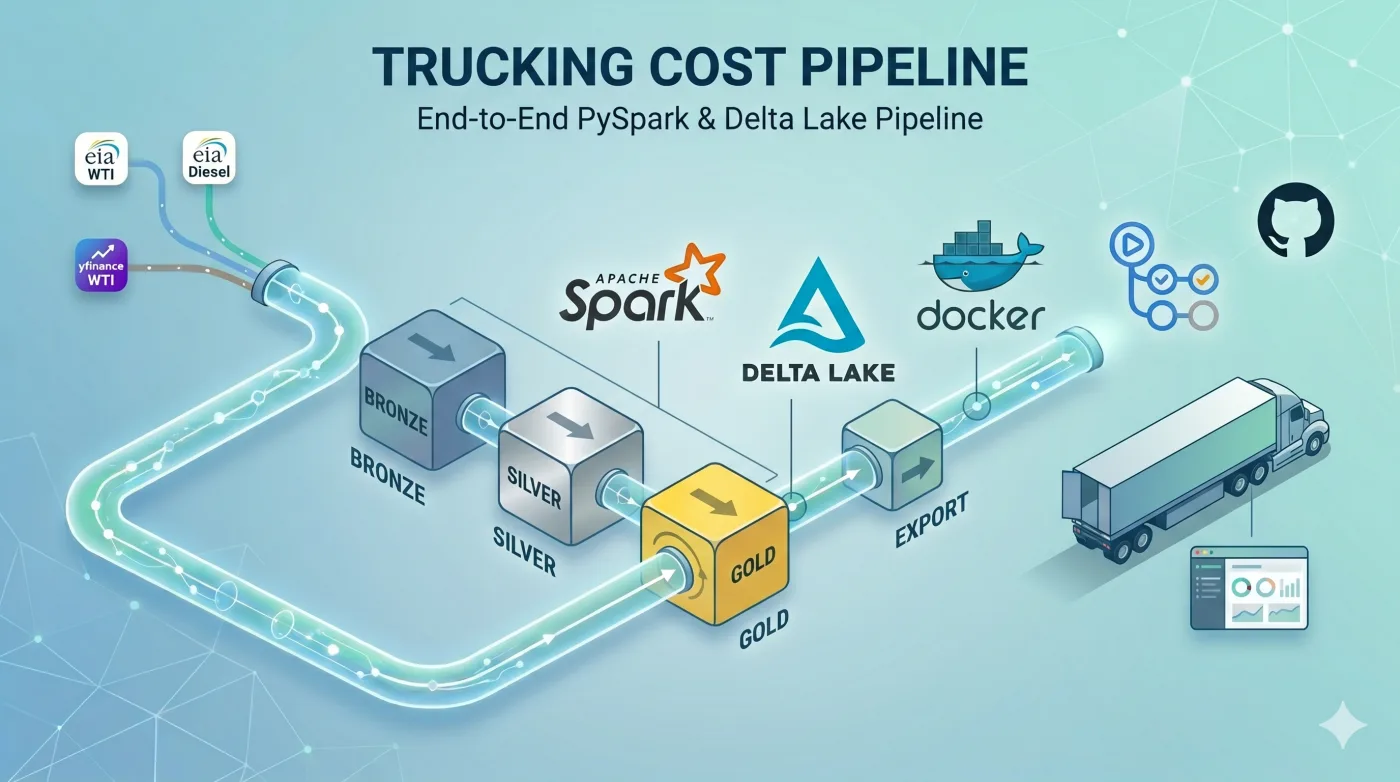
Every Tuesday afternoon, a pipeline pulls WTI prices (West Texas Intermediate, the main US crude oil benchmark) and diesel prices from the EIA (US Energy Information Administration).
The data flows through a medallion architecture in Apache Spark and Delta Lake. Bronze stores the raw data, silver delivers the cleaned data and gold consolidates what gets consumed. In the end, a JSON snapshot is published, feeding this dashboard with over 20 years of historical data (updated weekly).
The dashboard shows how diesel prices vary over time, their relationship with WTI and the main price shocks of recent years. Both series are public: WTI via yfinance and diesel via EIA Open Data API, free with an API key. The pipeline source code is available on GitHub.
How It Works
The stack was chosen based on what each tool brings to the project. PySpark contributes typed schemas and window functions, features that support dataset growth without requiring a rewrite. Delta Lake offers idempotent overwrites, removing the need for an external coordination layer. GitHub Actions runs the orchestration and stores the logs as an audit trail.
| Layer | Tool | Version |
|---|---|---|
| Compute | Apache Spark (PySpark) | 4.1.1 |
| Storage | Delta Lake | 4.2.0 |
| Orchestration | GitHub Actions | n/a |
| Tests | pytest | 9.x |
| Language | Python | 3.11 |
Apache Spark
Apache Spark is a processing engine for large data volumes. In this project, despite the modest volume, it adds value for two reasons: typed schemas, which protect the pipeline against silent changes at the sources (data origins), and window functions, which allow aligning series of different granularities on the same time axis and calculating operations such as lags and correlations directly.
The first application is in the bronze layer writer, which materializes a typed schema before any write to Delta Lake. If yfinance or the EIA changes a column or data type without notice, the next execution fails immediately, preventing corrupted history from being saved.
WTI_BRONZE_SCHEMA = StructType([
StructField("date", DateType(), True),
StructField("close", DoubleType(), True),
StructField("volume", LongType(), True),
StructField("ingestion_timestamp", TimestampType(), True),
StructField("ingestion_date", DateType(), True),
# ...
])
spark_df = spark.createDataFrame(pandas_df, schema=WTI_BRONZE_SCHEMA)The second point is combining the series on the same time axis. WTI is daily, while diesel is weekly. For both to be comparable, the diesel value needs to be propagated across every WTI trading day. A window function with last(..., ignorenulls=True) handles the operation directly:
window = Window.orderBy("date").rowsBetween(Window.unboundedPreceding, Window.currentRow)
filled = joined.withColumn(
"diesel_usd_gal",
last("price_usd_gal", ignorenulls=True).over(window),
)Delta Lake
Delta Lake is a storage layer on top of Parquet files that adds ACID transactions, versioning and upserts. ACID stands for Atomic (all-or-nothing), Consistent (data always valid), Isolated (no interference with parallel reads) and Durable (survives failures).
In this project, two features matter: replaceWhere, which makes the bronze write idempotent, and time travel, which versions every ingestion:
today = datetime.now(timezone.utc).date()
(
spark_df.write
.format("delta")
.mode("overwrite")
.option("replaceWhere", f"ingestion_date = '{today}'")
.partitionBy("ingestion_date")
.save(WTI_BRONZE_PATH)
)If the execution fails or is triggered again on the same day, the table remains intact, without accumulating duplicates. The same guarantee on a plain Parquet file would require a temporary path, directory renames and some lock mechanism.
The silver and gold layers use full overwrite, meaning they are rewritten in full on each execution. The incremental alternative, which recomputes only what changed, exists but requires tracking state between runs and managing checkpoints. Since the payload in this project stays under 10 MB, the extra effort is not worth it: rewriting everything is simple, fast and eliminates any chance of inconsistency between runs.
As a bonus, we get time travel for free: on each write, Delta Lake records a new version of the table and keeps the previous ones accessible by number or timestamp. In the bronze layer, this means any past execution can be queried as if it were the current state, useful for auditing in case it becomes necessary to roll back to a specific point.
GitHub Actions
GitHub Actions is the GitHub automation service, with free execution environments for public repositories. In this project, a single workflow file handles scheduling, tests and deploy.
The cron fires every Tuesday at 15:00 UTC:
on:
schedule:
- cron: '0 15 * * 2'
workflow_dispatch:Spark relies on Java libraries to integrate with Delta Lake, and these dependencies are downloaded by Ivy (a dependency manager from the Java/Scala ecosystem) on the first execution. Since the process takes a few minutes, caching the ~/.ivy2 directory between runs is worthwhile to bring the time down to seconds:
- name: Cache Ivy dependencies
uses: actions/cache@v4
with:
path: ~/.ivy2
key: ivy2-${{ runner.os }}-${{ hashFiles('pyproject.toml') }}An important decision was placing the tests before the pipeline, with fail-fast. This way, if something regressed in the gold layer logic, the execution is aborted before any Delta Lake write, and no corrupted data reaches the dashboard:
- name: Run tests
run: pytest tests/ -v
- name: Run pipeline (bronze -> silver -> gold -> export)
env:
EIA_API_KEY: ${{ secrets.EIA_API_KEY }}
run: |
python -m pipeline.bronze
python -m pipeline.silver
python -m pipeline.gold
python -m pipeline.exportClosing Notes
At the end of the exercise, the stack delivered what was expected of it. Spark and Delta Lake handled the data with types and idempotency, and GitHub Actions concentrated the execution cycle into a single workflow. The setup runs autonomously, with no infrastructure cost.
The intent was to brush up on concepts, and the result was more useful than expected: AI greatly accelerates the mechanical part, but still depends on human decisions to guide architecture, technical choices and fine-tuning. Knowing the tools remains what differentiates what gets delivered.
The pipeline source code is available on GitHub and the dashboard is open for browsing.
Thanks for reading.