Objetivo
Há um tempo venho trabalhando com o ecossistema do Google Cloud, o que me afastou de algumas ferramentas comuns na engenharia de dados. Resolvi então desenferrujar o conhecimento em Apache Spark, Delta Lake e GitHub Actions.
Usei o Claude Code como guia, fazendo do projeto uma espécie de aula prática que agilizou o desenvolvimento e reforçou alguns conceitos. Com o avanço da IA, criar soluções ficou cada vez mais simples. Ainda assim, conhecer as tecnologias por trás segue tendo valor para debater, questionar e direcionar o que se entrega.
Defini três itens para o teste: um dataset público, um pipeline capaz de rodar de forma automática e um resultado final que agregasse o mínimo de valor. Por trabalhar com logística e custos de transporte, escolhi os preços de combustível no mercado americano.
O que ela faz
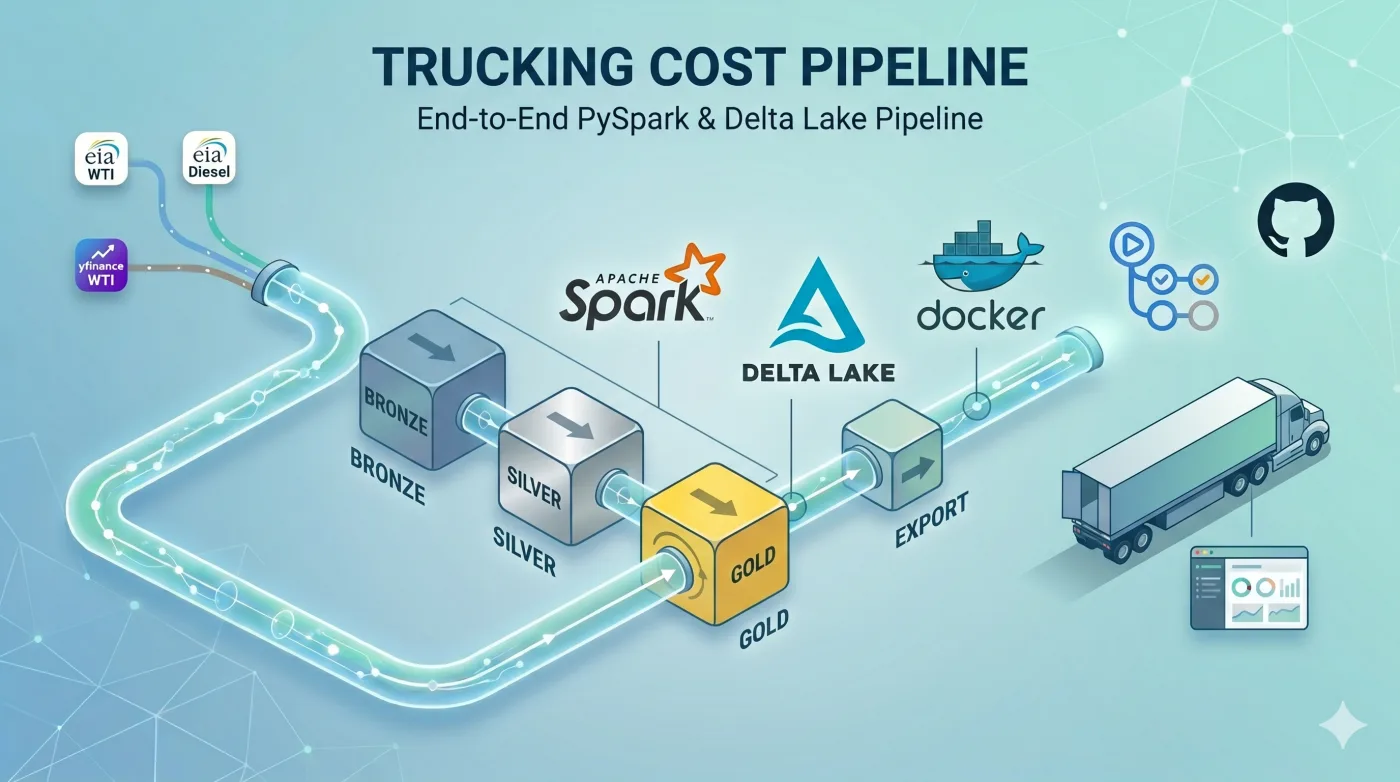
Toda terça à tarde, um pipeline obtém os preços do WTI (West Texas Intermediate, a principal referência de petróleo bruto americano) e os preços do diesel na EIA (US Energy Information Administration).
Os dados passam por uma arquitetura medallion em Apache Spark e Delta Lake. Bronze armazena o dado bruto, silver entrega o dado limpo e gold consolida o que vai para consumo. No fim, um snapshot JSON é publicado, gerando dados para este dashboard, com mais de 20 anos de dados históricos (sendo atualizado semanalmente).
O dashboard mostra como o diesel varia ao longo do tempo, sua relação com o WTI e os principais choques de preço nos últimos anos. As duas séries são públicas: WTI via yfinance e diesel via EIA Open Data API, gratuita mediante API key. O código do pipeline está disponível no GitHub.
Como funciona
A definição da stack levou em conta o que cada ferramenta agrega ao projeto. O PySpark contribui com schemas tipados e window functions, recursos que auxiliam no crescimento do dataset sem necessidade de reescrita. O Delta Lake oferece o overwrite idempotente, eliminando a necessidade de uma camada externa de coordenação. O GitHub Actions executa a orquestração, registrando os logs como trilha de auditoria.
| Camada | Ferramenta | Versão |
|---|---|---|
| Compute | Apache Spark (PySpark) | 4.1.1 |
| Storage | Delta Lake | 4.2.0 |
| Orquestração | GitHub Actions | n/a |
| Testes | pytest | 9.x |
| Linguagem | Python | 3.11 |
Apache Spark
O Apache Spark é um motor de processamento para grandes volumes de dados. No contexto do projeto, mesmo com volume modesto, ele agrega valor por dois motivos: schemas tipados, que protegem o pipeline contra mudanças silenciosas nas fontes (origens dos dados), e window functions, que permitem alinhar séries de granularidades distintas no mesmo eixo temporal e calcular operações como lags e correlações de forma direta.
A primeira aplicação ocorre no writer da camada bronze, que materializa um schema tipado antes de qualquer escrita no Delta Lake. Caso o yfinance ou a EIA alterem uma coluna ou um tipo de dado sem aviso, a execução seguinte falha imediatamente, evitando a gravação de histórico corrompido.
WTI_BRONZE_SCHEMA = StructType([
StructField("date", DateType(), True),
StructField("close", DoubleType(), True),
StructField("volume", LongType(), True),
StructField("ingestion_timestamp", TimestampType(), True),
StructField("ingestion_date", DateType(), True),
# ...
])
spark_df = spark.createDataFrame(pandas_df, schema=WTI_BRONZE_SCHEMA)O segundo ponto é a combinação das séries em um mesmo eixo temporal. O WTI é diário, enquanto o diesel é semanal. Para que ambos sejam comparáveis, o valor do diesel precisa ser propagado para todos os dias úteis do WTI. Uma window function com last(..., ignorenulls=True) resolve a operação de forma direta:
window = Window.orderBy("date").rowsBetween(Window.unboundedPreceding, Window.currentRow)
filled = joined.withColumn(
"diesel_usd_gal",
last("price_usd_gal", ignorenulls=True).over(window),
)Delta Lake
O Delta Lake é uma camada de armazenamento sobre arquivos Parquet que adiciona transações ACID, versionamento e upserts. ACID quer dizer Atomic (tudo-ou-nada), Consistent (dados sempre válidos), Isolated (sem interferir em leituras paralelas) e Durable (sobrevive a falhas).
No projeto, dois recursos importam: o replaceWhere, que torna a escrita do bronze idempotente, e o time travel, que versiona cada ingestão:
today = datetime.now(timezone.utc).date()
(
spark_df.write
.format("delta")
.mode("overwrite")
.option("replaceWhere", f"ingestion_date = '{today}'")
.partitionBy("ingestion_date")
.save(WTI_BRONZE_PATH)
)Se a execução falhar ou for disparada novamente no mesmo dia, a tabela permanece íntegra, sem acumular duplicatas. A mesma garantia em um arquivo Parquet puro exigiria path temporário, rename de diretórios e algum mecanismo de lock.
As camadas silver e gold usam full overwrite, ou seja, são reescritas por inteiro a cada execução. Existe a alternativa incremental, que recalcula apenas o que mudou, mas envolve rastrear o estado entre as execuções e gerenciar checkpoints. Como neste projeto o payload acaba ficando de 10 MB, esse esforço extra não compensa: reescrever tudo é simples, rápido e elimina qualquer chance de inconsistência entre as execuções.
De quebra, ganhamos o recurso de time travel gratuitamente: a cada escrita, o Delta Lake registra uma nova versão da tabela e mantém as anteriores acessíveis por número ou timestamp. Na camada bronze, isso significa que qualquer execução passada pode ser consultada como se fosse o estado atual, útil para auditoria caso seja preciso voltar a um ponto específico.
GitHub Actions
O GitHub Actions é o serviço de automação do GitHub, com ambientes de execução gratuitos para repositórios públicos. No projeto, utilizamos um único arquivo de workflow capaz de gerenciar o agendamento, testes e deploy.
O cron dispara toda terça às 15:00 UTC:
on:
schedule:
- cron: '0 15 * * 2'
workflow_dispatch:O Spark depende de bibliotecas Java para integrar com o Delta Lake, e essas dependências são baixadas pelo Ivy (gerenciador de dependências do ecossistema Java/Scala) na primeira execução. Como o processo leva alguns minutos, vale cachear o diretório ~/.ivy2 entre execuções para reduzir o tempo a segundos:
- name: Cache Ivy dependencies
uses: actions/cache@v4
with:
path: ~/.ivy2
key: ivy2-${{ runner.os }}-${{ hashFiles('pyproject.toml') }}Uma decisão importante foi posicionar os testes antes do pipeline, com fail-fast. Dessa forma, se algo regrediu na lógica do gold, a execução é interrompida antes de qualquer escrita no Delta Lake e nenhum dado corrompido chega ao dashboard:
- name: Run tests
run: pytest tests/ -v
- name: Run pipeline (bronze -> silver -> gold -> export)
env:
EIA_API_KEY: ${{ secrets.EIA_API_KEY }}
run: |
python -m pipeline.bronze
python -m pipeline.silver
python -m pipeline.gold
python -m pipeline.exportConsiderações finais
Ao final do exercício, a stack entregou o que se esperava dela. Spark e Delta Lake cuidaram do dado com tipos e idempotência, e o GitHub Actions concentrou o ciclo de execução em um único workflow. O conjunto roda de forma autônoma, sem custo de infraestrutura.
A intenção era desenferrujar conceitos, e o resultado foi mais útil do que o esperado: a IA acelera bastante a parte mecânica, mas continua dependendo de decisões humanas para guiar arquitetura, escolhas técnicas e ajustes finos. Conhecer as ferramentas segue sendo o que diferencia o que é entregue.
O código do pipeline está disponível no GitHub e o dashboard está acessível para consulta.
Obrigado pela leitura.