Problema
Toda empresa que atende cliente por voz gera áudio. SAC, vendas, fornecedores, suporte técnico. Há muito valor em saber o que foi dito, com qual tom ou se houve uma reclamação. O mercado vende isso como "call analytics" e costuma cobrar valores elevados.
A tese deste post é simples: no Google Cloud Platform (GCP), com Vertex AI + Gemini é possível criar uma pipeline com duas Cloud Functions por um custo muito baixo. Sem produto SaaS, sem contrato anual, sem licença por usuário.
Use case
O caso de uso natural (ligações de call center) envolve áudio sensível, e particularmente, gostaria de validar a tese em uma base pública e replicável. Cheguei então ao OpenF1, que disponibiliza todas as comunicações de rádio entre piloto e engenheiro da temporada de 2025 da Formula 1.
O dataset tem três pontos que funcionam bem para demonstração: diálogos curtos, contexto rico (etapa da temporada, equipe, piloto...) e um tema lúdico o suficiente para virar um dashboard público.
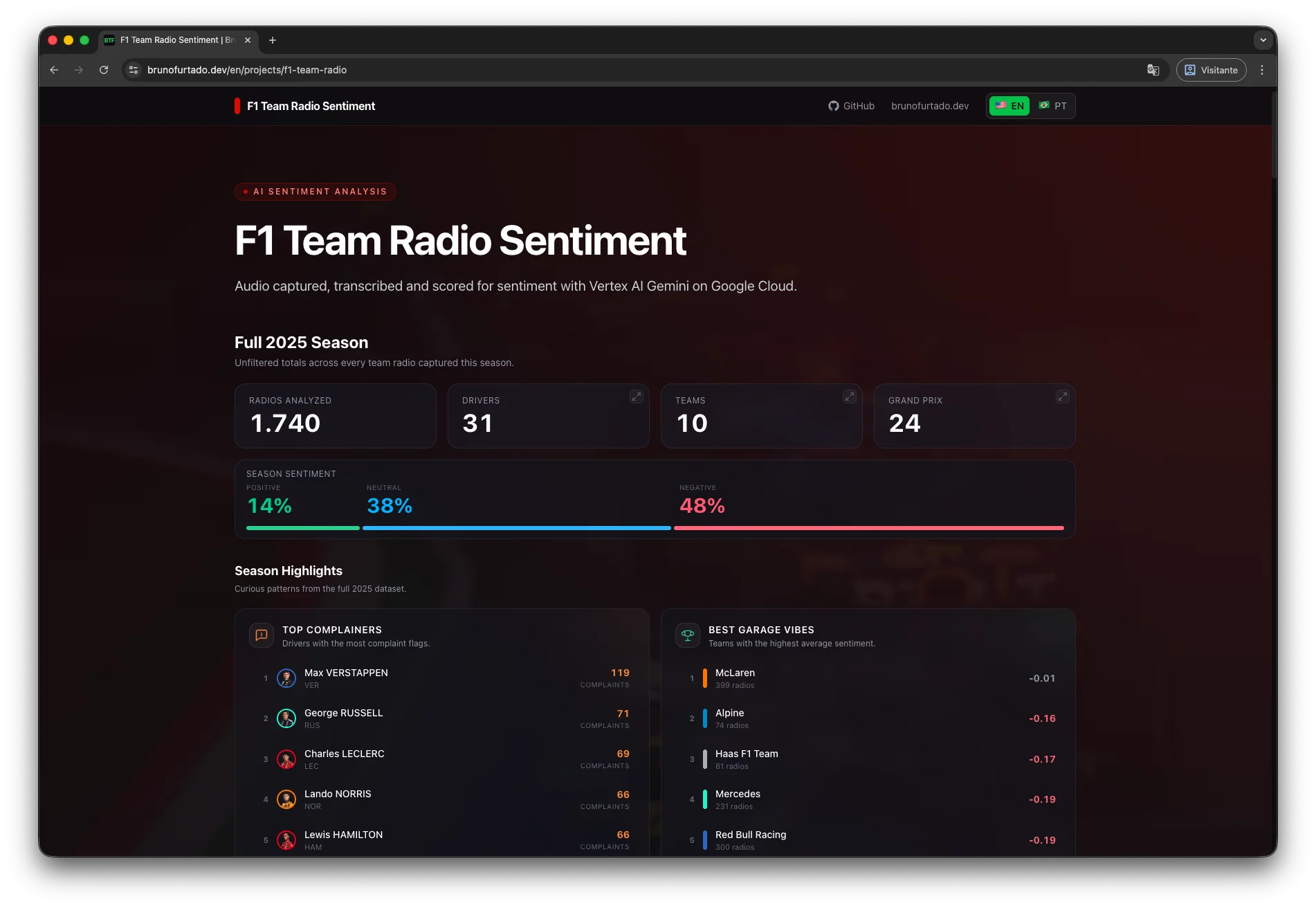
A fonte de dados é a Formula 1, mas o pipeline é o mesmo para qualquer áudio de chamada. Trocar o coletor pelo SFTP, API ou bucket não gera grandes esforços.
Arquitetura
O pipeline é composto por duas Cloud Functions (Gen2) em Python, além do BigQuery como camada de armazenamento e consulta.
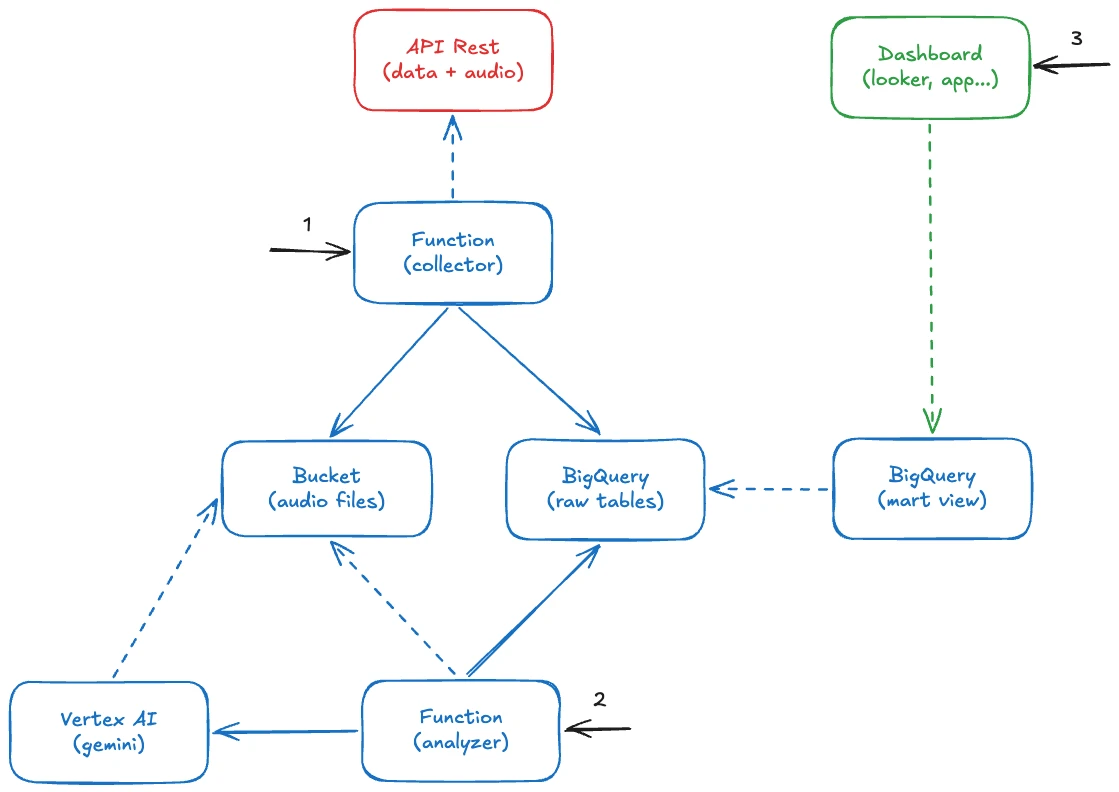
Coleta dos dados
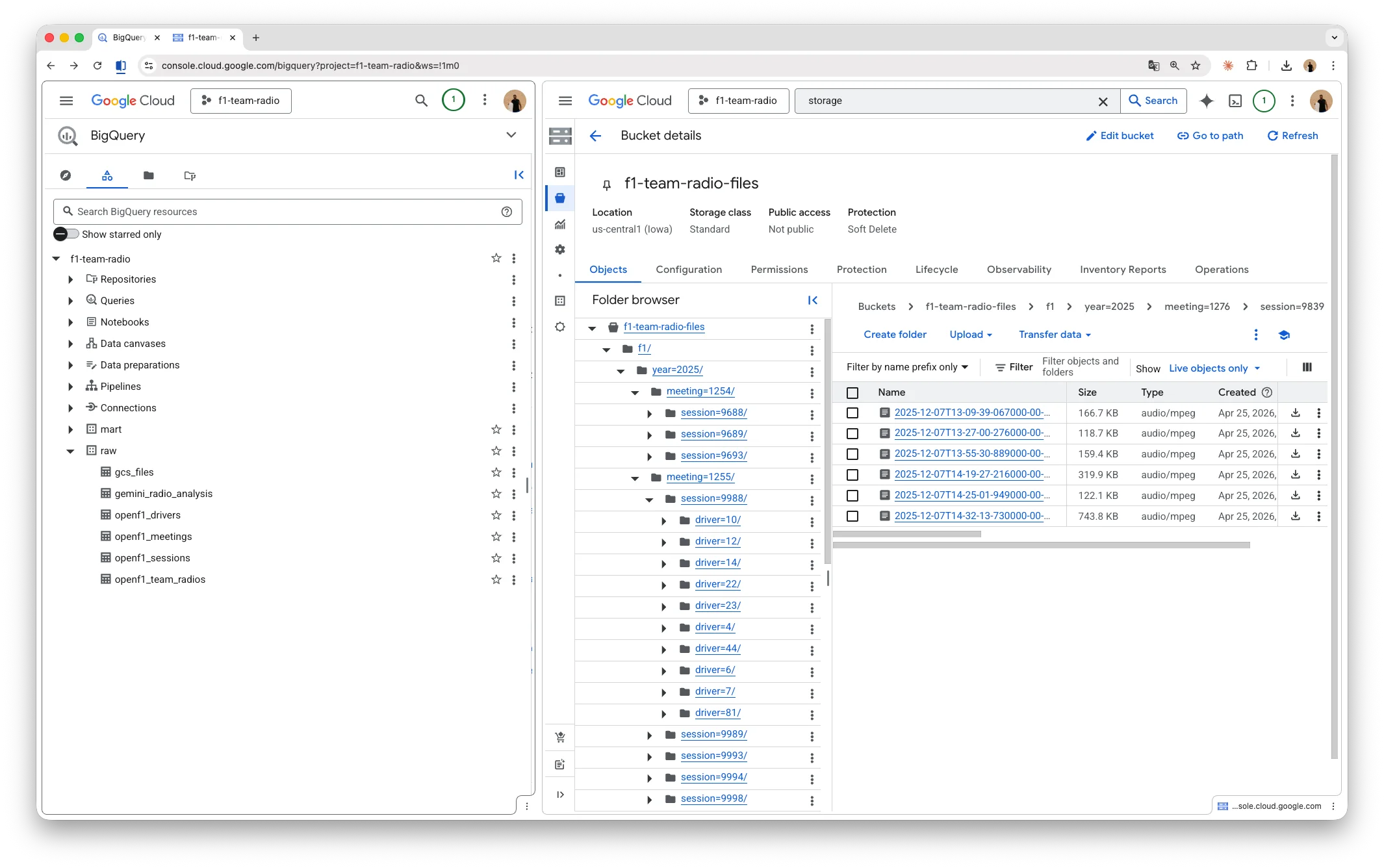
A primeira função lê metadados da API do OpenF1, baixa os MP3s em paralelo (respeitando o rate limit) e salva os arquivos em um path hierárquico (year=.../meeting=.../session=.../driver=.../*.mp3) no Google Cloud Storage (GCS). Cada áudio, por sua vez, acaba se tornando um registro na tabela raw.openf1_team_radios do BigQuery.
Analise dos áudios
A segunda função obtém os áudios pendentes, enviando-os para o Gemini que realiza a transcrição e analise de sentimento para, finalmente, persiste o JSON estruturado como registro na tabela raw.gemini_radio_analysis.
Estratégia de processamento
O uso de um watermark em SQL puro acaba informando quais áudios ainda não foram processados. Cada execução obtém o que ficou para trás (padrão útil para qualquer pipeline com dados sendo enviados de forma incremental).
SELECT t.gcs_uri, t.driver_number, t.meeting_key, t.session_key
FROM `your-project-id.raw.openf1_team_radios` t
LEFT JOIN `your-project-id.raw.gemini_radio_analysis` a USING (gcs_uri)
WHERE a.gcs_uri IS NULLEscolha de LLM
Quanto ao modelo de LLM, a escolha foi o gemini-2.5-flash pois, para áudio curto, ele entrega transcrição e classificação a um custo muito baixo. O gemini-3.1-pro-preview entra apenas como fallback, e essa decisão também é uma estratégia de custo. O flash tem uma janela de contexto menor (quando o áudio é grande o suficiente para extrapolar esse limite, a chamada falha).
def analyze_one(row):
try:
return call_gemini_with_retry(row, 'gemini-2.5-flash', 'us-central1')
except Exception:
# áudio grande demais, falha não-recuperável no flash; vai pro pro
return call_gemini(row, 'gemini-3.1-pro-preview', 'global')Criação do prompt
O system prompt define o papel do modelo e os campos que ele deve produzir:
You are an analyst of Formula 1 team radio communications.
You will receive a short audio clip plus a JSON metadata block describing
the context (driver, team, session type, Grand Prix, country).
Produce a structured JSON output with:
- transcription: list of timestamped segments
- sentiment_score: number between -1.0 and 1.0
- sentiment_label: positive | neutral | negative
- emotion: calm | focused | frustrated | angry | excited | disappointed
- is_complaint: boolean
- complaint_target: car | tyres | strategy | weather | other_driver | team | none
- topic: pace | tyres | strategy | weather | incident | position | fuel | brakes | engine | communication | other
- summary: 1-2 sentence summary in English
- language_detected: ISO 639-1 code
Response estruturada
Ao solicitar JSON como retorno do prompt, o caminho mais adequado é declarar a estrutura via response_schema, com enums no centro:
RESPONSE_SCHEMA = {
'type': 'object',
'properties': {
'sentiment_score': {'type': 'number'},
'sentiment_label': {
'type': 'string',
'enum': ['positive', 'neutral', 'negative'],
},
'emotion': {
'type': 'string',
'enum': ['calm', 'focused', 'frustrated', 'angry', 'excited', 'disappointed'],
},
'is_complaint': {'type': 'boolean'},
'complaint_target': {
'type': 'string',
'enum': ['car', 'tyres', 'strategy', 'weather', 'other_driver', 'team', 'none'],
},
'topic': {
'type': 'string',
'enum': [
'pace', 'tyres', 'strategy', 'weather', 'incident',
'position', 'fuel', 'brakes', 'engine', 'communication', 'other',
],
},
# transcription, summary, language_detected, is_positive_outcome...
},
'required': [...],
}Os enums fazem o trabalho pesado. Como o Gemini só pode responder com um valor permitido, você nunca precisa de regex, normalização ou pós-processamento.
A chamada em si é curta, com try/except envolvendo o generate_content para que o fallback do snippet anterior funcione:
contents = [
genai_types.Content(
role='user',
parts=[
genai_types.Part.from_uri(file_uri=row['gcs_uri'], mime_type='audio/mpeg'),
genai_types.Part.from_text(text=f'Context metadata:\n{metadata_json}'),
],
)
]
config = genai_types.GenerateContentConfig(
system_instruction=PROMPT,
response_mime_type='application/json',
response_schema=RESPONSE_SCHEMA,
audio_timestamp=True,
)
try:
response = client.models.generate_content(
model='gemini-2.5-flash',
contents=contents,
config=config,
)
except Exception:
# propaga para analyze_one decidir entre retry e fallback no pro
raiseNote que o áudio entra como Part.from_uri apontando direto para o GCS. Não precisa baixar o arquivo na função para depois subir para o Vertex.
Resultado
O retorno de cada áudio tem a forma do schema:
{
"transcription": [
{ "start_time": "00:01", "start_time_seconds": 1.0, "speaker": "engineer", "text": "Box, box, box. Soft tyres." },
{ "start_time": "00:04", "start_time_seconds": 4.2, "speaker": "driver", "text": "Copy. Coming in." }
],
"sentiment_score": 0.1,
"sentiment_label": "neutral",
"emotion": "focused",
"is_complaint": false,
"complaint_target": "none",
"is_positive_outcome": false,
"topic": "strategy",
"summary": "Engineer instructs the driver to pit for soft tyres; driver acknowledges.",
"language_detected": "en"
}Esse objeto vai direto para o BigQuery numa tabela onde transcription é modelada como RECORD REPEATED. A partir daí, qualquer ferramenta de BI consome sem ETL adicional: Looker Studio, Metabase, Power BI ou até uma planilha ligada via BigQuery.
Para alimentar o dashboard, criei uma view na camada mart que consolida os campos consumidos pelo front (agregados por GP, sessão, time e piloto). A view concentra a lógica de negócio no BigQuery e mantém o front enxuto, sem transformação por cima do JSON.
Em cima dela, um script Python roda ao final do pipeline e exporta um snapshot como JSON estático, servido pelo front em /projects/f1-team-radio. Esse caminho funciona aqui porque os dados são 100% públicos e podem viver no bundle do site. Em uma solução de produção, com áudio sensível, o desenho correto seria um backend lendo a view sob demanda, com autenticação, autorização e controle de acesso.
Custo ($)
Foram cerca de 1800 áudios, aprox. 260 MB no total, com média de 150 KB por arquivo. A duração quase nunca passa de 10 segundos.
| Serviço | Custo |
|---|---|
| Vertex AI (Gemini) | R$42,28 |
| Cloud Run Functions | R$0,00 |
| BigQuery | R$0,00 |
| Cloud Storage | R$0,00 |
| Artifact Registry | R$0,00 |
| Cloud Build | R$0,00 |
| Total | R$42,28 |
Em resumo, R$0,023 por chamada, sem comprometer a qualidade do output.
Use cases reais
Trocando a fonte do áudio e ajustando os enums do schema, ele cobre vários casos práticos:
- SAC: priorizar tickets de clientes irritados pelo nível de frustração detectado. Agrupar reclamações por alvo para entender o que está quebrando no produto.
- Vendas: identificar objeções recorrentes em ligações de SDR. Comparar o tom médio por etapa do funil para descobrir onde a conversão azeda.
- Fornecedores: registro automático de tom em negociações longas, útil para revisitar acordos antes de renovação.
- Sucesso do cliente: medir evolução do sentimento em check-ins recorrentes com contas-chave, sem depender de NPS pós-call.
Sobre o projeto
O código completo está disponível no GitHub e o resultado pode ser visto no dashboard.
Se quiser se aventurar, sinta-se à vontade para clonar e adaptar para a sua fonte de áudio.
Obrigado pela leitura.